
技術情報
インテル® Xeon® スケーラブル・プロセッサー ベンチマーク結果
第6世代 Intel Core アーキテクチャのサーバ向けプロセッサー インテル® Xeon® スケーラブル・プロセッサーがリリースされました。E5-2600 v2、v3、v4・・・と続いてきたファミリー名称が「v5」にならず、スケーラブル・プロセッサーとして一新され、ソケット数に依存しないCPU型番となりました(新たにBronze、Silver、Gold、Platinumという製品レベル分けが導入されました)。新マイクロアーキテクチャ「Skylake」を採用し、前世代と比べてSIMDベクトル幅が2倍のAVX-512拡張命令セットに対応しており理論性能が2倍となっている点と、メモリチャンネル数が6本(前世代の4本に比べて1.5倍)に増えた点が特長です。
AVX-512で増大したロード・ストア要求に答えるべく各ユニットもあわせて増強され、1cycleあたり 32DP(倍精度演算)、64SP(単精度演算)をこなせる強力なハードウェアとなっています。また、コア数が最大28となり、コア数が多くなっても網の直径が小さく、全体的に近い経路を使える2Dメッシュバス接続方式に変更されました。また、キャッシュ容量比についても、従来に比べてL2キャッシュの容量が相対的に大きく変更され、熱流体や量子化学など、キャッシュへの連続的なアクセスが多いアプリケーションの高速化に効果的な設計となっています。
インテル® Xeon® スケーラブル・プロセッサーの性能を調査するため、スケーラブル・プロセッサーのエンジニアリングサンプル(ES品)と旧ファミリーのE5-2699 v4を搭載した2-wayマシンで各アプリケーションのベンチマークを実施して実効性能を比較しました。最新・最先端の技術情報をいち早くお届けする都合上、この度ES品での評価をご報告しており、実際の製品との差異が入る可能性がございますことをご了承下さい。ベンチマークで使用した検証環境は次表のとおりです。
| CPU | インテル® Xeon® スケーラブル・プロセッサー ES品 | Intel Xeon E5-2699 v4 |
|---|---|---|
| アーキテクチャ | 第6世代Intel Coreプロセッサー | 第5世代Intel Coreプロセッサー |
| CPUクロック | 1.8GHz | 2.2GHz |
| AVX時CPUクロック | 1.8GHz(推定) | 1.8GHz |
| CPUコア数 | 28core | 22core |
| L2キャッシュ | 28MB | 5.5MB |
| Last Levelキャッシュ | 38.5MB | 55MB |
| 対応メモリ規格 | DDR4 | DDR4 |
| 対応メモリFSB | 2666 MHz | 2400 MHz |
| 使用メモリFSB | 2400 MHz | 2400 MHz |
| 倍精度理論性能 | 1612.8 GFlops(推定) ( = 1.8GHz * 28core * 32 ) | 633.6 GFlops ( = 1.8GHz * 22core * 16 ) |
| 理論メモリ帯域 | 115.2 GB/s | 76.8 GB/s |
| CPU | インテル® Xeon® スケーラブル・プロセッサー ES品* 2CPU (計56core) | Intel Xeon E5-2699 v4 * 2CPU (計44core) |
|---|---|---|
| メモリ | DDR4 192GB 2400MHz | DDR4 128GB 2400MHz |
| HDD | 1TB SATA600 7200rpm | |
| OS | CentOS 7.2.1511 x86_64 | |
| コンパイラ | Intel Parallel Studio XE 2017 Update 2 Intel Parallel Studio XE 2018 ベータ版 |
|
| MPI | Intel MPI 2017 Update 2 Intel MPI 2018 ベータ版 |
|
| ノード数 | 1 | |
HPL
HPLはスーパーコンピュータの性能ランキング『Top 500 Supercomputer Sites』 ( https://www.top500.org/ ) で用いられているベンチマークプログラムです。連立方程式の解を求めるプログラムで、浮動小数点演算の性能をFLOPS単位、つまり1秒間に処理できる浮動小数点演算命令の数で性能を評価します。HPLでCPUの実効性能を計測し、理論性能どおりの実効性能の向上があるかを調査しました。
HPLはIntel Parallel StudioでAVX-512とAVX2とAVXのCPU最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。ホットスポットで使用されるMKLが性能を大きく左右するため、AVX-512最適化が謳われているIntel Parallel Studio XE 2018 ベータ版を使用しました。
- HPL
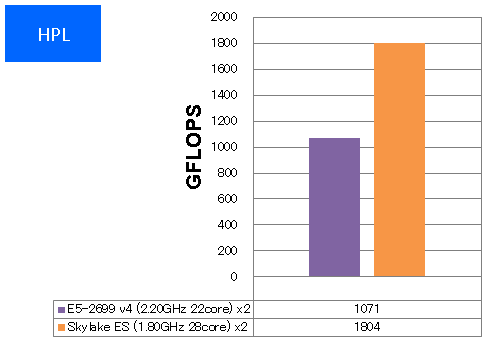
結果:1ノード2CPUで1.8TFLOPSに到達
1ノードでのCPUコア総数が56に増大し、さらにAVX-512による理論性能2倍の効果から、1ノード2CPUで 1.8TFLOPS を超える性能を達成しました。ES品の理論性能に比べると実行効率は6割弱となっており、前世代CPUで8割程度発揮できていた状況と比べると実行効率は低いですが、これはMKLやコンパイラがAVX-512への最適化途上にあるためと考えられます。とはいえ、前世代の1.68倍もの実効性能を出せていますので、Skylakeマイクロアーキテクチャが飛躍的な性能向上をもたらすことを確認するのに十分な結果です。CPU演算インテンシブなプログラムにおける実効性能向上の目安として捉えていただければと思います。
STREAM (Triad)
STREAMはメモリ帯域性能の測定に多用されているベンチマークプログラムです。その中でもTriadというプログラムは巨大な一次元ベクトルの積和を行うOpenMP並列プログラムで、並列動作させてメモリ入出力の全体性能をMB/s単位で評価します。STREAM Triadで理論帯域どおりの実効帯域の向上があるかを調査しました。 STREAMはIntel Parallel StudioでAVX-512最適化オプションを有効にしてビルドしたものでベンチマークを実施しました。
結果:前世代の1.39倍のメモリ帯域性能を達成
CPUあたりのメモリチャンネル数が6となり、STREAM Triadの実効性能で前世代の1.39倍のメモリ帯域性能を達成しました。メモリチャンネル数の増大はSandy Bridge世代の登場以来の出来事で、以降メモリ動作周波数増加による1割程度の向上が続いていた状況と比べて、段違いの帯域増大です。この結果は、FFTや熱流体など、メモリ帯域性能による律速に悩まされてきたアプリケーションユーザーにとって、久々に期待の持てるニュースと言えるでしょう。
Amber16
Amberは生体分子シミュレーションソフトウェアのひとつです。Intel Parallel StudioのAVX-512とAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを行いました。
AmberのpmemdのGPU版公式サイトで配布されている408,000原子のCellulose NVEのインプットと、25,095原子のNucleosome GBのインプットを、pmemdで計算したときの経過時間を測定しました。
結果:クロック比をふまえると大きく性能向上し、56並列まで順調にスケール
経過時間の値だけを見るとSkylake ES品の方が遅く見えますが、実際はCPUのベースクロックがE5-2699 v4に比べて82%に低いもので比較していますので、それをふまえるとSkylake ES品の方が大きく速い結果となっています。さらに、従来同様、56コア並列まで並列性能が良好にスケールすることが確認できました。CPUコア数の多いCPUを選択することが推奨されます。
VASP
VASPは密度汎関数法による平面波・擬ポテンシャル基底を用いた第一原理電子状態計算プログラムパッケージです。このプログラムは並列実行時にCPU-メモリ間帯域を多く使用する傾向があります。Intel Parallel StudioでAVX-512とAVX2とAVXのCPU最適化を有効にしてビルドをしたものでベンチマークを実施しました。
216原子・512原子・1000原子でのPAW GGA計算とUSPP計算を行い、経過時間の比較をしました。また、計算負荷が大きく複雑な計算の例として、以前お客様よりご依頼のありました実材料の計算インプットファイル(詳細は明かせませんが、40原子数における DFT:PAW-PBE計算)についても経過時間を取得しました。
結果:極めて大きく性能向上し、さらにフルコア並列まで性能スケール
CPUのベースクロックがE5-2699 v4に比べて82%に低いものであるにも関わらず、ほとんどのベンチマークでSkylakeのES品の方が短時間に計算できています。4~8並列など、メモリ帯域の律速があらわれにくい条件においても速度向上が見られることから、CPU自体、特にAVX-512が良好に機能していると推測されます。
さらに、驚くべきことに、メモリ帯域で律速しがちであったVASPが、56並列まで性能スケールしています。これは、ボトルネック原因となっていたCPU-メモリ間帯域性能が、Skylakeマイクロアーキテクチャにてメモリチャンネル6本になって増大したことが大きく影響していると考えられます(メモリ帯域の実効性能向上については本ページ内STREAMベンチマークも参照下さい)。 44並列にて特異的に経過時間が長い現象は、過去のE5-2600 v4ファミリーでのベンチマークでも既知で、11という割り切れない素数の倍数が、並列処理上好ましくないためと考えられます。
Gaussian 16
量子化学計算のデファクトスタンダードであるGaussianでのベンチマークを行いました。使用したGaussian16は、AVX2に最適化されたGaussian社標準のBinary版パッケージです(AVX-512には未対応です)。 Gaussianパッケージに付属のtest0397に加えて、分子数や基底関数数の異なるいくつかのDFT計算について実行時間を比較しました。
結果:56スレッド並列まで順調な性能向上を発揮
HPLと同様に、CPUバウンドな性質が度々観察されてきたGaussianでは、スレッド並列数を56に増やしても順調な性能向上が得られました。CPUコアの多い構成が望ましいと言えます。
Amber同様、経過時間の値だけを見るとSkylake ES品の方が遅く見えますが、実際はCPUのベースクロックがE5-2699 v4に比べて82%に低いもので比較していますので、それをふまえるとSkylake ES品の方が速い結果となっています。
複数ジョブ同時実行
逐次計算、あるいは小さな並列数で計算を実行すべき状況では、同時に数多くの計算を高スループットにこなす能力がCPUに求められます。HPLとVASPについて、同一の計算ジョブを同時に複数実行し、プロセス数が増えた時の性能劣化率(1プロセス実行時を100%とします)を測定しました。
結果:性能劣化率が大幅に縮小
HPL・VASPとも、E5-2699 v4と比べて大幅に性能劣化率が縮小しています。AVX-512をはじめとする大量のロード・ストア要求に答えるべく増強されたCPU内各種ユニットによって、多数の計算を高スループットにこなす頑強な処理基盤が実現できています。搭載コア数がさらに増えたインテル® Xeon® スケーラブル・プロセッサーを複数ジョブで稼働率高く運用できる裏付けとなる結果と言えます。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)