
技術情報
インテル® Xeon® E5-2690とNVIDIA® Tesla® M2090の行列積における実効性能比較
昨今、GPGPUによる大並列計算と、新世代CPUアーキテクチャによる性能向上がHPCの高速化におけるホットな話題となっています。ですが、GPU全コアの比較対象がCPU1コアになっていたりするなど、これらのアプローチが正面きって性能比較を行った場合に、それらの実効性能がどの程度であるのかは明らかではありません。そこで、Byte/Flopが比較的大きい2次元行列積を用いて、インテルMKL、PGIアクセラレータ、CUDA shared memory最適化、CUBLAS、の4アプローチの性能比較を行いました。ベンチマークの結果、2012年現行モデルであるインテルXeon E5-2690の2CPUの1筐体と、2012年現行GPUであるNVIDIA Tesla M2090の1基がほぼ同等の実効性能を達成することがわかりました。
比較するアプローチ
次表のアプローチを比較対象としました。それぞれの、コードの特徴、実装の手軽さ、実装に必要なスキル、必要な機材、ソースコードの保守性についても挙げていますので参考にしてください。
| アプローチ | CPUでMKLのマルチスレッド並列を使用 | PGIアクセラレータコンパイラのOpenACCを使用 | CUDAで手作業でshared memory最適化を施す※ |
|---|---|---|---|
| コードの特徴 | CPUアーキテクチャに最適化された高速な数値計算アルゴリズムを採用 | コンパイラがソースコード解析して最適化したコード | 手作業でCUDAアーキテクチャに最適化させたソースコード |
| 実装の手軽さ | BLASのAPIを呼ぶコードを書いてMKLをリンクするだけで最適化されたCPUコードを使える | ディレクティブをコメントとして挿入するだけでGPUコードを使える | CUDAプログラミング手法とGPUアーキテクチャに合わせた繊細なソースコード記述が必要 |
| 実装に必要なスキル | BLASのAPIを知っておく必要がある | ディレクティブの適用方法を理解しておく必要がある | shared memoryを用いた最適化技術を習得しておく必要がある |
| 必要なソフトウェア | インテル MKL(Level 3 BLASライブラリ) | CUDA,PGIアクセラレータコンパイラ | CUDA |
| ソースコードの保守性 | BLASのAPIを用いたコードに置き換わる | ディレクティブがコメントとして挿入された元コードが残る | CUDAのAPIとプログラミング作法に特化する |
※CUDAのマニュアルのプログラミング例に従って最適化を行いました。
評価対象アプリケーション
2次元行列積を採用しました。これはGPGPUの有効性が明白なEmbarrassingly Parallel計算と異なり、Byte/Flopが比較的大きいです(2flopに対し3要素のloadと2要素のstore)。ディレクティブやshared memory最適化においては、最適化が適用されやすいと考えられる3重ループによる実直な実装をベースとしました。MKLおよびCUBLASではsgemmとdgemmを用いました。
ベンチマーク結果
評価環境を次表に示します。
| 評価環境(1) | 評価環境(2) | 評価環境(3) | |
|---|---|---|---|
| CPU | インテル Xeon X5690(6コア,3.46GHz)×2 | インテル Xeon E5-2690(8コア,2.90GHz)×2 | インテル Xeon X5690(6コア,3.46GHz)×2 |
| コンパイラー | インテル Visual Fortran Composer XE Windows版 | インテル Visual Fortran Composer XE 2011 Linux版 | PGI Accelerator Workstation 11.9 Windows版 |
| GPU | なし | なし | NVIDIA Tesla M2090×1基 |
| 数値計算ライブラリ | インテル MKL 10.3(Composer付属) | インテル MKL 10.3(Composer付属) | CUBLAS(CUDA付属) |
| CUDA | なし | なし | CUDA 4.0 |
| OS | Windows 7 Professional x64 SP1 | CentOS 6.2 | Windows 7 Professional x64 SP1 |
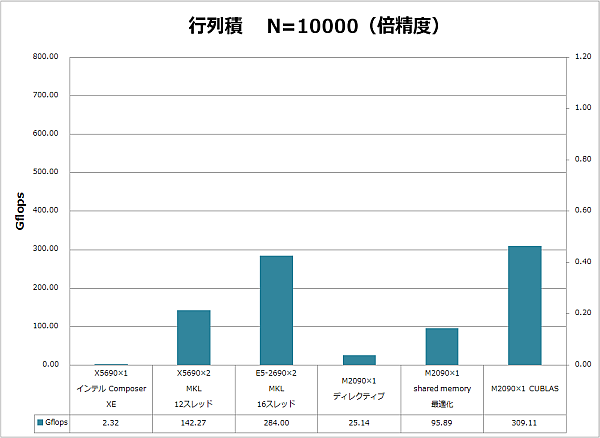
行列の行数=列数=10,000での、単精度浮動小数点数と倍精度浮動小数点数それぞれにおける2次元行列積の計算性能(Gflops)を次図に示し、その詳細を次表に示します。GPGPUアプローチの計算時間には、GPUメモリ-ホストメモリ間のデータ転送時間も含んでいます。
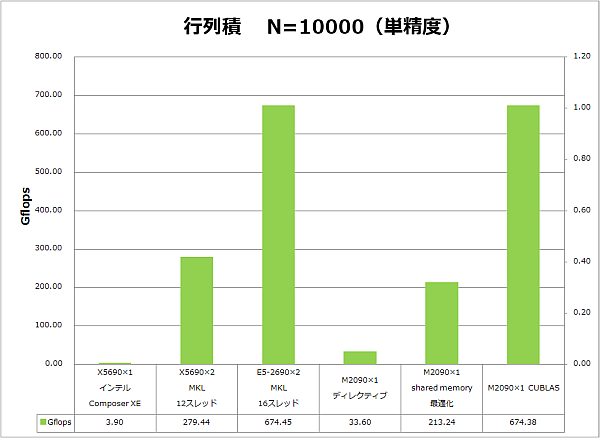
| 単精度 | N | 計算時間[秒] | Gflop | Gflops | 理論性能 | 実行効率 |
|---|---|---|---|---|---|---|
| X5690×1 インテル Composer XE | 10000 | 478.16 | 1863 | 3.90 | 27.68 | 14.1% |
| X5690×2 MKL 12スレッド | 10000 | 6.67 | 1863 | 279.44 | 332.16 | 84.1% |
| E5-2690×2 MKL 16スレッド | 10000 | 2.76 | 1863 | 674.45 | 742.40 | 90.8% |
| M2090×1 ディレクティブ | 10000 | 55.43 | 1863 | 33.60 | 1331 | 2.5% |
| M2090×1 shared memory最適化 | 10000 | 8.74 | 1863 | 213.24 | 1331 | 16.0% |
| M2090×1 CUBLAS | 10000 | 2.76 | 1863 | 674.38 | 1331 | 50.7% |
| 倍精度 | N | 計算時間[秒] | Gflop | Gflops | 理論性能 | 実行効率 |
|---|---|---|---|---|---|---|
| X5690×1 インテル Composer XE | 10000 | 801.78 | 1863 | 2.32 | 13.84 | 16.8% |
| X5690×2 MKL 12スレッド | 10000 | 13.09 | 1863 | 142.27 | 166.08 | 85.7% |
| E5-2690×2 MKL 16スレッド | 10000 | 6.56 | 1863 | 284.00 | 371.2 | 76.5% |
| M2090×1 ディレクティブ | 10000 | 74.08 | 1863 | 25.14 | 665 | 3.8% |
| M2090×1 shared memory最適化 | 10000 | 19.43 | 1863 | 95.89 | 665 | 14.4% |
| M2090×1 CUBLAS | 10000 | 6.03 | 1863 | 309.11 | 665 | 46.5% |
この結果、次がわかりました。
- E5-2690の2CPU16コアと、Tesla M2090の1基がほぼ同等の実効性能となりました。
- 理論性能に対する実行効率はCPUが76~90%と高いのに対し、GPUは約50%と低いです。
- CUBLASの計算速度は、shared memoryを用いて手作業で最適化したコードに比べて約3倍となっています。
なお、X5690に比べてCPU周波数が16%ダウンしているにもかかわらずE5-2690で大きく性能向上しているのは、L3キャッシュ(E5-2690ではLLC)の1.6倍のサイズ増大、CPU-CPU間のQPI接続の2.5倍の速度向上、CPU-メモリ間の1.6倍の転送速度向上、AVXによる理論上2倍の演算幅増大が貢献していると考えられます。
結論
2次元行列積のようにメモリバンド幅が多少要求されるアプリケーションでは、2012年現行モデルであるインテル Xeon E5-2690の2CPUの1筐体と、2012年現行GPUであるNVIDIA Tesla M2090の1基が、ほぼ同等の実効性能を達成することがわかりました。 実効性能を考慮した高速化アプローチの選定には、アプリケーションのByte/Flop要求具合を勘案しつつコア数勝負でGPGPUに賭けるか、メモリアクセス速度勝負(キャッシュサイズとQPI接続速度)でCPUに賭けるかを考えることが肝要です。また、(shared memoryの最適化などのように)高速化にソースコードの大きな変更を要する場合もあるため、ソースコードの保守性も考慮に含めるべきです。
インテル® Xeon® E5-2600シリーズ搭載製品についてはこちらを参照ください。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)