
技術情報
Gaussian 16 ベンチマーク結果
2017年早々に待望のGaussian 16がリリースされました。インテル® Xeon® Haswellマイクロアーキテクチャ以降で利用可能なAVX2拡張命令セットに対応したバイナリが新たに利用可能になりました。また、Gaussian社とNVIDIA社とPGIの協力(プレス記事とGTC2014での技術発表資料を参照下さい)によって、新たにDFT計算とHF計算でGPGPUに対応しました。Gaussian社の、計算速度への飽くなき意欲が伝わってきます(GPUベンチマークについては現在取得中のため、次回更新時の掲載を予定しておりますことをご容赦下さい)。
Gaussian 16の基本的な性能を掴むため、Haswellマイクロアーキテクチャを採用したワークステーション用途CPUでベンチマークを取得しました。計算内容は、2017年時点で現実的な条件におけるDFTでのOpt(構造最適化)計算とFreq(振動数)計算、そして弊社が定点観察してきたtest397インプットにおけるGaussian 09との比較です。ベンチマークの結果、B3LYP/6-31G(d,p)の基底関数1620個のOptが44コアで2.7時間強、Freqが3.5時間強で完遂しました。また、test397ではデフォルトの計算精度が高くなったためにGaussian 09と比べて遅い結果となりましたが、AVX2版が速度向上に大きく貢献することを確認しました。
| CPU | Intel Xeon E5-2699 v4 * 2CPU (計44core) |
|---|---|
| メモリ | DDR4 128GB 2400MHz |
| HDD | 1TB SATA6Gbps 10000rpm |
| OS | Red Hat Enterprise Linux 7.3 x86_64 |
| Gaussian | 16 Rev. A.03 AVX2-enabled |
Gaussian 16
ベンチマークに使用したGaussian 16は、AVX2に最適化されたGaussian社標準のBinary版パッケージです。比較対象のGaussian 09はAVXに最適化されたGaussian社標準のBinary版パッケージです。
まず、2017年時点でGaussianユーザーにとって現実的な規模・精度条件で、よく使われるDFT法でのOpt計算とFreq計算の計算速度を測定しました。具体的には、test397インプットで使われてきたValinomycin分子で、RB3LYPのまま、基底関数系を6-31G(d,p)に差し替えたものを用いました。以下に経過時間(秒)と、スケーラビリティを図示します。なお、Opt計算では34回のイタレーションが実行された結果となっています。
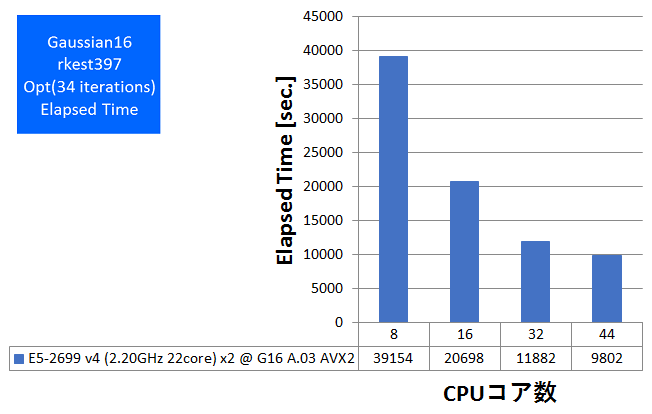
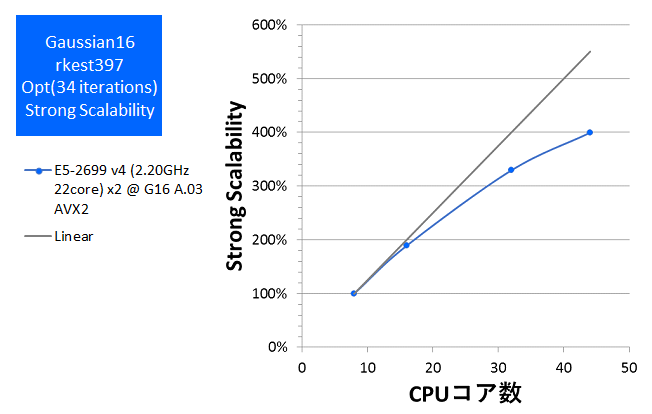
- Opt(Valinomycin分子、原子数168、基底関数数1620、RB3LYP/6-31G(d,p))
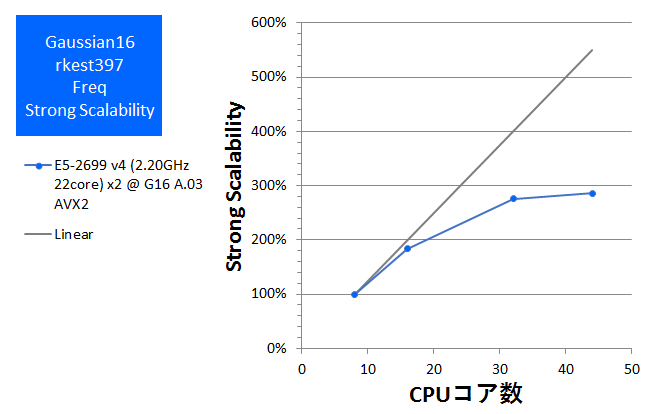
- Freq(Valinomycin分子、原子数168、基底関数数1620、RB3LYP/6-31G(d,p))
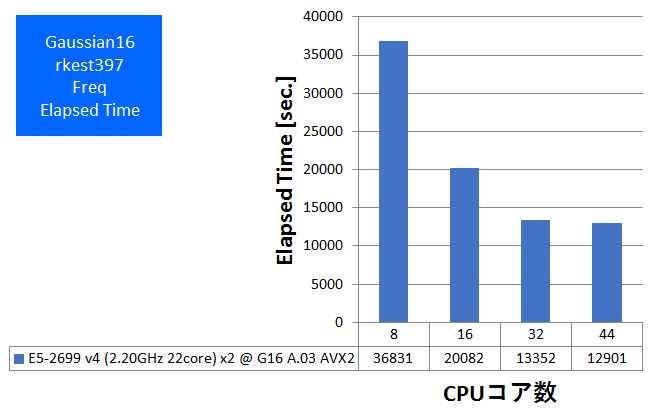
特長:現実的規模のOpt計算が2.7時間強、Freq計算が3.5時間強で完遂
Opt計算は、今回用いたCPUで最大の並列数である44コア(スレッド)まで、遜色なくスケールして速度向上を確認できました。Freq計算も44並列まで性能向上が見られましたが、Opt計算よりも並列化効率(強スケーラビリティ)が低くなっており、DFT法でのFreq計算が主たる用途の場合には、ノードあたり32コアまでの構成が効率的でお勧めです。Gaussian 16の計算時間の目安としていただければと存じます。
続いて、弊社で定点観測としてベンチマーク取得してきた test397インプットの性能評価です。従来同等の計算内容でベンチマーク取得をした結果、次の結果となりました。比較対象として、同マシンでGaussian09で取得した結果も載せています。
- test397(Valinomycin分子、原子数168、基底関数数882、RB3LYP/3-21G、SP)
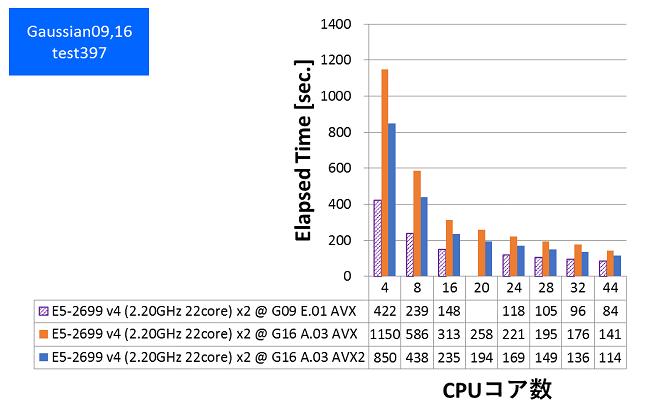
特長:Gaussian 16 AVX2版がGaussian 16 AVX版に比べて1.24~1.35倍の高速化
Gaussian 09のAVX版に比べると、Gaussian 16のAVX版は遅くなりました。これは、Gaussian 16でいくつかの新しい計算タイプ(例えば、TD-DFT振動数や非調和ROAなど)の計算精度を保証するために、デフォルトの積分精度が10-10から10-12へ細かくなり、デフォルトのDFTグリッドがFineGridからUltraFineへ変更されたためです。
その一方で、Gaussian 16では新たに対応したAVX2版が、Gaussian 16のAVX版に比べて1.24~1.35倍の速度向上を達成しています。Gaussian 09のSSE4版とAVX版を比較した場合に(弊社ベンチマーク記事)、1.12~1.14倍程度の速度向上しか効果が無かったことと比べますと、Gaussian 16のAVX2版は大変効果的に機能しています。したがって、Gaussian 16をお使いになるお客様には、AVX2版とHaswellマイクロアーキテクチャCPU(インテル® Xeon® プロセッサー E5-2600 v3・v4 ファミリー対応製品)の組み合わせを強くお勧めいたします。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)