
技術情報
NVIDIA® Tesla® K40・K80 Amber14 ベンチマーク比較
Keplerアーキテクチャを採用したNVIDIA® Tesla® シリーズのTesla® K80とTesla® K40がリリースされています。両者ともきわめて高い浮動小数点数演算性能を有しています。
今回、Amber14でベンチマークを取得し、CUDA版の実効性能、使用GPU数を増やした時のスケーラビリティを評価しました。
NVIDIA® Tesla® K40・K80のAmber14 ベンチマーク結果
Amberは生体分子シミュレーションソフトウェアのひとつです。Amber14の並列計算向けPMEMDのCUDA版では、複数GPU環境における並列性能スケーラビリティを改善するため、GPUDirect™ 2.0のP2P通信を積極的に用いるように実装されています(もしGPU間でP2P通信が利用できない場合は、従来通りMPIによるホストメモリを介した通信が行われます)。
今回、GPUを4枚搭載可能なIntel Xeon E5-2600 v3 ファミリー2ソケットマシンで、Tesla® K80とTesla® K40を搭載させてベンチマークを取得しました。機材繰りの都合で、K40使用時はCPUにE5-2693 v3、K80使用時はE5-2697 v3を用いましたが、Amber PMEMDのCUDA版は使用GPU数だけCPUコアを使用し、分子動力学計算の全体をGPU上で実行するため、このCPU差による影響はとても小さいと考えています。P2P通信は同一のPCIバスに接続されていることが必要条件であるため、今回のマシンではCPUソケット間をまたいだ複数のGPU間ではP2P通信を行えなくなっています。ベンチマークで使用した検証環境をまとめると次表のとおりです。
| 製品 | HPC5000-XHGPU4TS |  |
|---|---|---|
| CPU | Intel Xeon E5-2697 v3 × 2CPU (計28コア) 及び | |
| Intel Xeon E5-2698 v3 × 2CPU (計32コア) | ||
| メモリ | DDR4 64GB 2133MHz | |
| GPU | Tesla K80 × 4GPU 及び Tesla K40 × 4GPU | |
| OS | CentOS 6.5 x86_64 | |
| CUDA | CUDA 6.5 | |
| コンパイラ | Intel Compiler 14.0.3 | |
| MPI | OpenMPI 1.6.5 | |
| Amber | Amber14 bugfix 9 + AmberTools14 bugfix 23 |
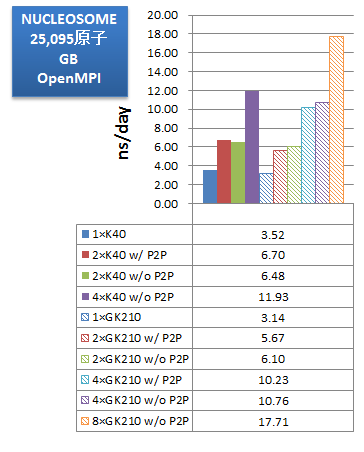
ベンチマークでは、使用するGPUを、K40が1枚、K40が2枚(P2P通信有効)、K40が2枚(P2P通信無効)、K40が4枚(P2P通信無効)、K80のGK210が1基、K80のGK210が2基(P2P通信有効)、K80のGK210が2基(P2P通信無効)、K80のGK210が4基(P2P通信有効)、K80のGK210が4基(P2P通信無効)、K80のGK210が8基(P2P通信無効)、のパターンで比較しました。インプットにはAmber14のGPU版サイトで配布されている公式ベンチマークスイートを用いました。
次に、取得したベンチマークの性能をns/dayで示します。「ns/day」は性能比較用の単位で、計算時間を基に、1日あたり何ns分の分子動力学計算を実行可能か、を示した数字です(数字が大きいほど、高性能、高速となります)。
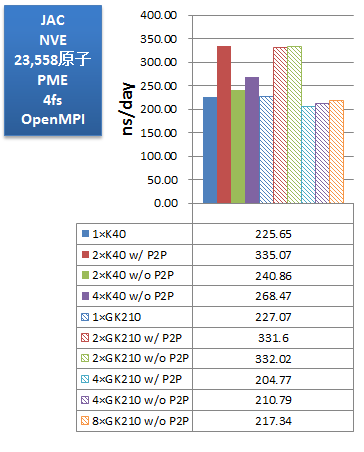
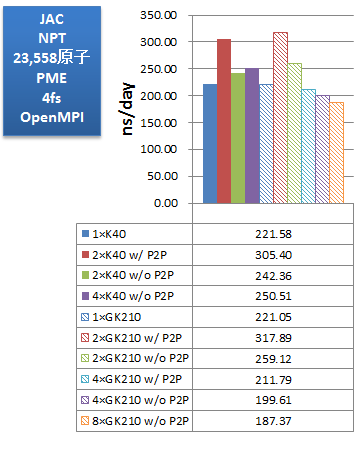
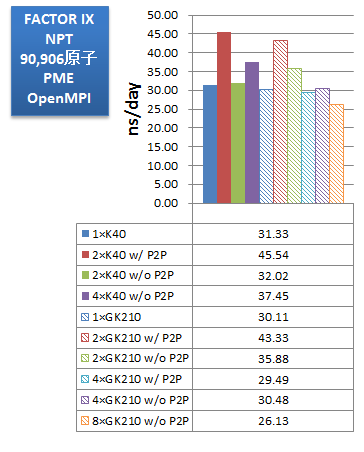
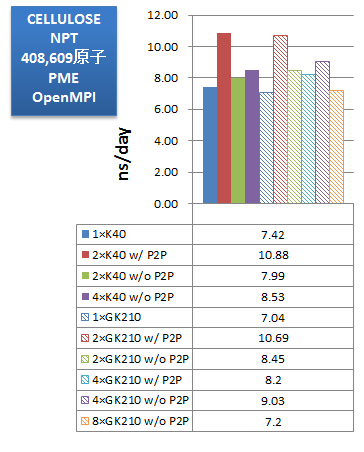
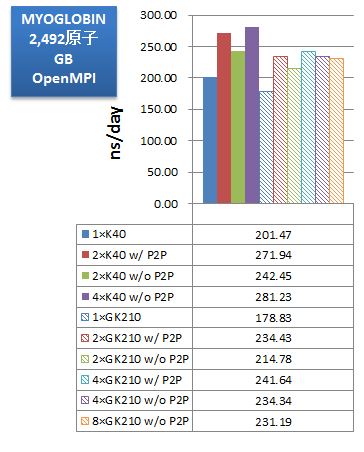
PME計算では、JAC(DHFR)・FACTOR IX・CELLULOSEのいずれの系においても、今回のマシンではGPUが2基(P2P通信有効)の場合が最も高性能を示しました。また、そのときK80・K40ともほぼ同等の実効性能となっており、価格対性能で考えるとGPU数の多いTesla® K80がお勧めできると言えます。また、GPUを4基もしくは4枚に増やしても実効性能が伸びないことは、使用GPU数や搭載GPU数の選択において参考になります。
GB計算では、対象系が大きくなるにつれてGPUによる加速効果が大きくあらわれました。Amber PMEMD CUDA版のGBについての論文(DOI: 10.1021/ct200909j)によれば、(Amber11の頃の記事ではありますが、)力のデータをGPU間で同期させるためにイタレーション毎にMPI_AllGatherを3回実行していることから、小さな系では通信オーバーヘッドが目立って性能が横並びとなり、大きな系では計算時間の短縮効果が顕著になったと考えられます。また同記事によればGPU間では負荷分散を行っていないとのことで、このことが、GPUを4枚まで増やしても性能が向上することに寄与していると考えられます。
関連リンク
インテル® Xeon® プロセッサー E5-2600 v3 ファミリー、NVIDIA® Tesla® シリーズGPU対応製品
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)