
技術情報
NVIDIA® Tesla® K80 ベンチマーク結果
GPU Direct 2.0 P2P転送機能、およびAmber14の性能について更新いたしました。[2015/08/13更新]
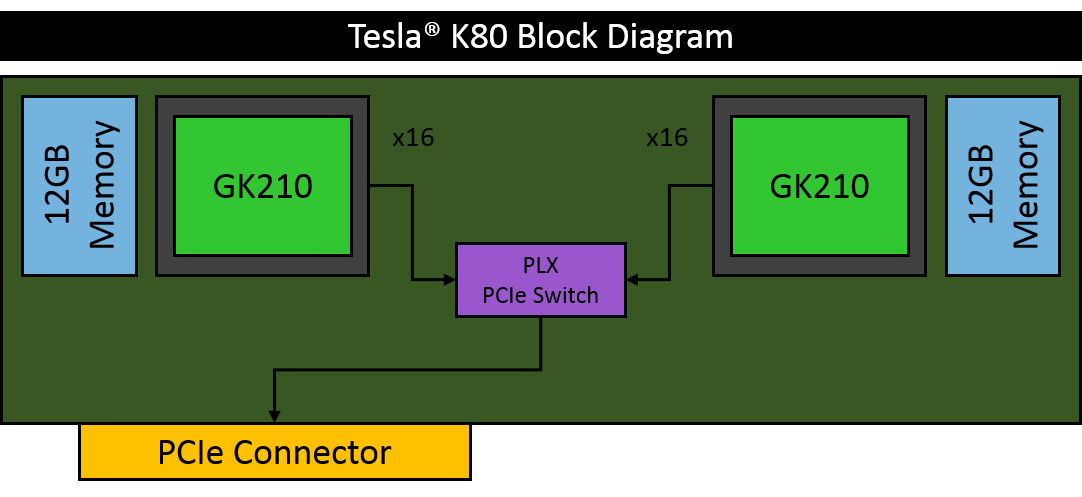
こちらで特集しておりますように、Keplerアーキテクチャを採用したNVIDIA® Tesla®シリーズの最上位モデル Tesla® K80がリリースされました。主な特徴は、従来のTesla® 製品と同じPCIのFHFL 2スロット分のサイズあたりで、単精度で5.60TFlops(GPU Boost時 8.74TFlops)、倍精度で1.87TFlops(GPU Boost時 2.91TFlops)もの、きわめて高い浮動小数点数演算性能を有する点です。Tesla® K80は、新登場のGPUチップ GK210を2基搭載しています。GK210は、Tesla® K40のGK110Bと比べて、SMX(Streaming Multiprocessor eXtreme)あたりのレジスタファイルの容量が256KBから512KBに、シェアードメモリの容量が64KBから128KBに倍増しています。これによりGPUはより長い時間ビジーになることができ、これは外部メモリとの送受信の削減、アプリケーションの実行効率向上と性能向上に寄与します。
Tesla® K80の利用に関する留意事項
Tesla® K80の導入を検討されている方は、以下の点に留意下さい。
Tesla® K80の1カードが2GPUデバイスとして扱われます
▶前述のとおり、Tesla® K80はカード1枚あたりGK210チップを2基搭載しています。nvidia-smiコマンドでは、GK210チップごとにGPUデバイスとして認識されていることを確認できます。
▶GDDR5メモリはGK210チップそれぞれの側に個別に存在し、それらは共有されていません。そのため、物理的形状こそ1枚のカードですが、システムユーザ側からは、独立したGPUが2基接続されているかのように操作することになります。すなわち、2つのGK210のメモリの間でデータを受け渡しする際は、CUDAのメモリコピー処理等で明示的にコピー手続きを実行する必要があります。
▶前述のTesla® K80カードのFlops値は、その半分のFlops値を有するGK210チップ×2個分の値です。並列処理オーバーヘッドがきわめて少ない、「Embarrassingly Parallel」な並列性を有するアプリケーションであればGK210チップ2個分の実効性能向上が得られるでしょうし、そのような用途を想定したGPU製品と見ることも可能と思います。
GPUDirect™ 2.0 Peer-to-Peer(P2P)転送機能の異常動作が確認されています
BIOS更新とLinux上でのPCI設定変更により解消されました [2015/08/13更新]
▶GPUDirect™ 2.0のP2P転送機能とは、同一PCIeバスに繋がれたFermi以降GPU間で、ホストメモリを介さず低遅延に通信できる機能です。弊社測定では、データサイズに依らず通信時間35%短縮の効果を確認できました。これは、複数GPU対応アプリケーションのPCIバスボトルネックの回避に有効です(例えばAmber14など)。既に複数GPU向けにCUDAアプリケーションを実装されたデベロッパーの皆様は、活用頂いていることも多いと思います。
▶今回のベンチマークでは弊社GPGPUワークステーションHPC5000-XHGPU4TSに計4枚のTesla® K80を接続して用いました。GPUDirect™ 2.0のP2P転送機能は、同一のPCIeバスに繋がれた2枚のTesla® K80カードの間では有効になるかと予想されましたが、予想に反し、同一のPCIeバスに繋がれたTesla® K80カードの間では有効となりませんでした。これまでのTesla® K40等のようにはP2P転送機能を使えない※ことに注意が必要です。
※ P2P転送機能を使用できない原因としては、Tesla® K80内のPCIeスイッチを経由したGPU(GK210)へのP2P転送に、E5-2600 v3 ファミリーのCPU内のPCIeスイッチ機能が対応していないのではないか、という点を弊社では疑っておりますが、その裏付け資料はございません。ただし、この仮説に基づき、CPU以外の個別のPCIeスイッチでGPUカードを接続する形の弊社検証機でTesla® K80を複数接続して動作確認いたしましたところ、このPCIeスイッチに接続されたどのGPU(GK210)の間でもP2P転送できると確認が取れましたので、この仮説には説得力があると考えております。
▶Tesla® K80カード内の2基のGK210の間では、P2P転送機能は有効となりました。しかし、後述のAmber14ベンチマークでも見られるように、このP2P転送機能を使うと、動くもののGPU処理が異常に遅くなる現象が確認されました。これはホストメモリを介して通信しながら計算させた場合よりも桁違いに遅いものでしたので、実用上Tesla® K80のP2P転送機能は役に立たないと言えます。この遅くなる現象の原因としては、状況的に、Tesla® K80上でのP2P通信の実行において何らかのハードウェアボトルネックが生じたことと思われますが、詳しくは特定できておりません。
▶マザーボードメーカー様およびNVIDIA様より本件についてサポート情報をご提供いただきました。それによると、BIOSを更新し、さらにLinux OS上で Tesla® K80に関するTCP設定の変更を行うことで、P2P転送の挙動が改善する可能性が高いとのことでしたので、弊社にてTesla® K80の挙動について再検証を行いました。[2015/08/13更新]
GK210チップ間で速度差が見られることがあります
▶今回のベンチマークで利用可能な8個のGPUデバイスの間で、数%の計算速度差が見られました。おそらくGPU Boost機能と筐体内の熱などの関係で生じたと思われます。計算速度を追求する際には、何回か速度サンプリングを行い、比較的速度が高いGPUデバイスを選んで使うなどの確認をされた方が良いかと思います。
Tesla® K80のベンチマーク結果
Tesla® K80の性能を調査するため、Tesla® K80を4枚搭載したマシンで各アプリケーションのベンチマークを実施して実効性能を測定しました。ベンチマークで使用した検証環境は次表のとおりです。
| CPU | Intel Xeon E5-2698 v3 * 2CPU (計32core) ※Amber14 ベンチマークのみ Intel Xeon E5-2697 v3 *2CPU (計28core) [2015/08/13更新] |
|---|---|
| メモリ | DDR4 128GB 2133MHz |
| OS | CentOS 6.5 x86_64 |
| CUDA | CUDA 6.5 |
| コンパイラー | Intel Compiler 14.0.3 |
| MPI | Open MPI 1.6.5およびIntel MPI 4.1.3 |
| Amber | Amber14 bugfix 9 + AmberTools14 bugfix 23 |
| GROMACS | GROMACS 4.6.7 |
行列積
Tesla® K80のGPUデバイス(GK210)1基の実効性能を測るべく、2次元行列積のベンチマークを取得しました。行列演算ルーチンにはCUDA Toolkit 6.5付属のCUBLASのSGEMM/DGEMMを使用しました。測定にあたっては、Tesla® K80のGPU Boost性能を最大限に引き出すべく、nvidia-smiコマンドの -ac オプションを使ってMemoryクロックとGraphicsクロックを最大に設定しました。
行列の行数=列数を10,000 / 18,000 / 24,000に変えたときの、単精度浮動小数点数と倍精度浮動小数点数それぞれにおける2次元行列積の計算性能(GFlops)を次図に示します。また、参考比較として、今回のベンチマーク環境のCPU E5-2698 v3の2CPUでマルチスレッド並列版MKLを用いた場合の計算性能も記載しています。
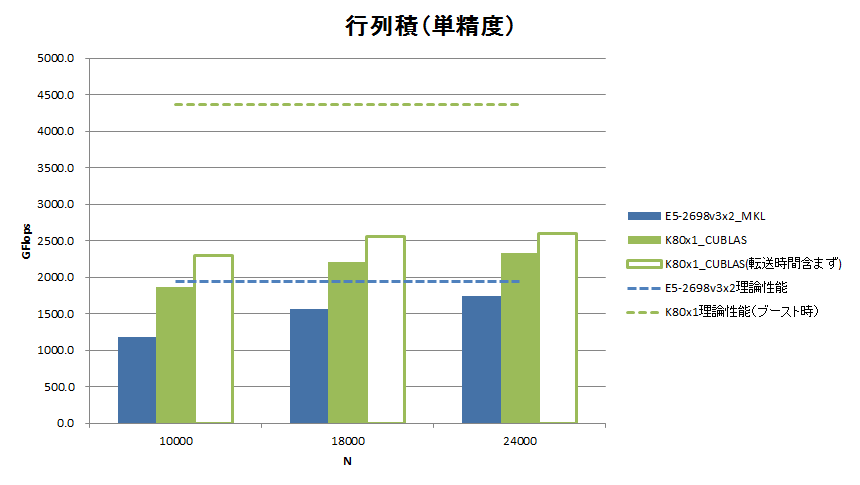
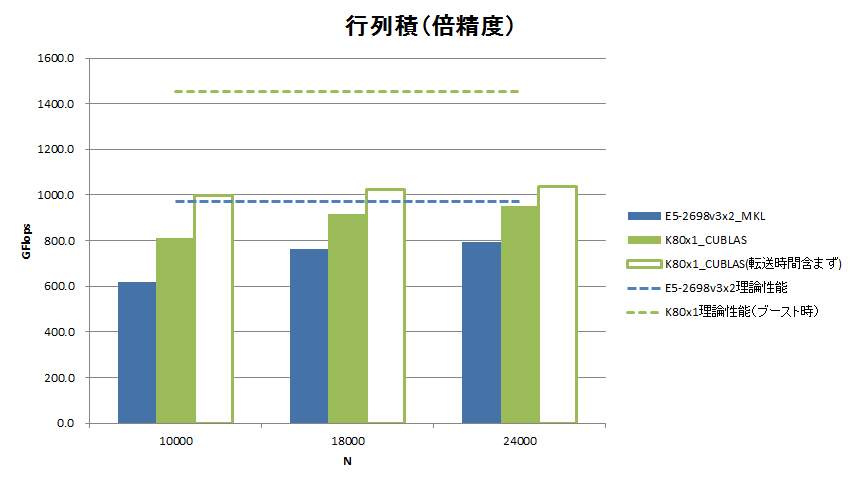
単精度では転送時間を含めない純計算性能で2,600GFlops、倍精度では1,038GFlopsの性能を達成しました。転送時間を含めると単精度で2,331GFlops、倍精度で949.8GFlopsの達成です。2013年3月頃のTesla® K20での弊社ベンチマークと比べてみると、カードあたりで(Tesla® K80はGK210の2基で単純に2倍すると)、単精度でK20の2.93倍、倍精度でK20の2.70倍の性能を有しています。TDPはK20が225W、K80が300Wですので、Flops/Wは単精度で2.20倍、倍精度で2.02倍に向上しています。一方、CPUとの性能比較では、HaswellアーキテクチャになってCPUの実効性能が倍増し、GPUとの差を詰めている様子が如実に表れています。
GROMACS
GROMACSはフリーの分子動力学アプリケーションです。単精度浮動小数点演算の性能が大きく影響する特性から、それを得意とするGPUを活用するGPGPU高速化が実装されています。(ただし後述のAmber14と異なり、P2P転送機能を使うようには実装されていません。)
以前のTesla® K40でのベンチマークと同様に、ベンチマークには、指定サイズのボックスを水分子で満たして分子動力学計算を行う弊社独自のインプットを用いました。水分子のみの系では実用的な計算結果にはなりませんが、生体分子などの水を多用する系の計算において、実効性能の傾向の把握に十分であると確認しています。
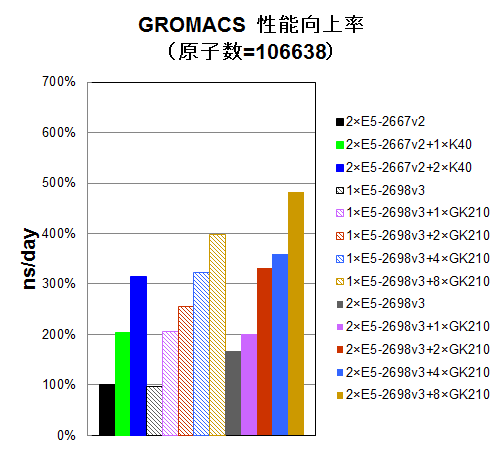
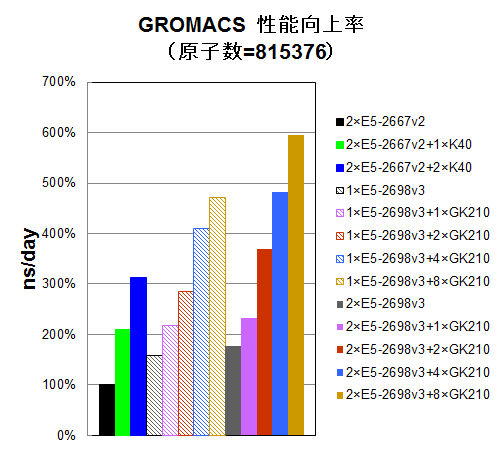
水分子インプットで原子数を1,836 / 7,671 / 106,638 / 815,376個に変えながら、CPU16コアのみ使用時、 CPU16コアとGK210を1/2/4/8基使用時、CPU32コアのみ使用時、CPU32コアとGK210を1/2/4/8基使用時についてns/dayを測定しました。参考比較として、一世代前のCPU E5-2667 v2の2CPU使用時と、それにTesla® K40を1/2枚追加した時についても、プロットいたしました。E5-2667 v2の2CPU使用時を100%として、性能向上率をプロットしました。
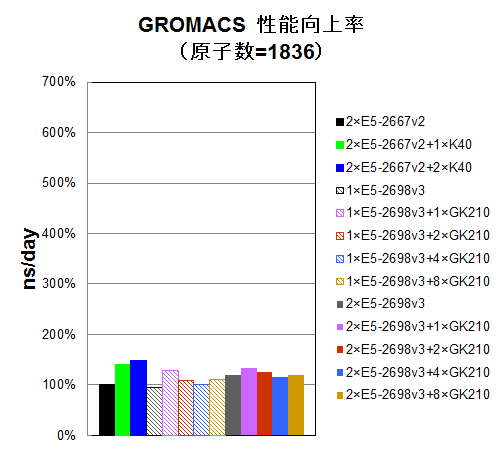
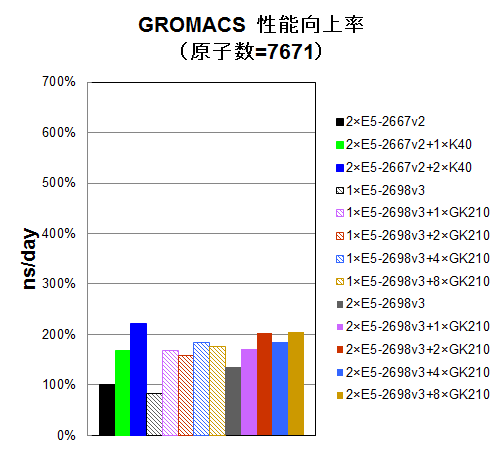
原子数が10,000個以下のインプットでは、総じてGPU加速効果が薄い傾向にあります。このような系で計算される場合には、CPU版のGROMACSをお使いいただくか、あるいはせいぜい1枚のTesla® K40を加えてGPU版GROMACSをお使いいただくことをお勧めいたします。
原子数が100,000近くになりますと、GPU加速効果が顕著になりますが、Tesla® K80カードを2枚用いてもTesla® K40カード2枚と同程度の性能となっていますので、費用対性能の面からTesla® K40カードを2枚用いる構成がお勧めです。Tesla® K80カード4枚のGK210 8基並列では性能スケーラビリティが伸び悩んでいます。
原子数が1,000,000近くなりますと、さらにGPU加速効果が大きくなり、Tesla® K80カード 2枚による性能向上が十分Tesla® K40を引き離し、費用対性能の面からもTesla® K80カード2枚構成がお勧めになります。ただし、依然として、Tesla® K80カード4枚のGK210 8基並列では性能スケーラビリティが伸び悩んでいます。
Amber14 [2015/08/13更新]
Amberは生体分子シミュレーションソフトウェアのひとつです。Amber14の並列計算向けpmemdのCUDA版では、複数GPU環境における並列性能スケーラビリティを改善するため、GPUDirect™ 2.0のP2P通信を積極的に用いるように実装されています(もしGPU間でP2P通信が利用できない場合は、従来通りMPIによるホストメモリを介した通信が行われます)。
Tesla® K80のP2P転送機能に関して、前回(2015/02/17報告)と同じバイナリを使用して再検証ベンチマークを行いました。前回報告との比較を含め以下記載いたします。
▶Tesla® K80カード1枚での2並列計算
CUDA_VISIBLE_DEVICES環境変数を用いて、明示的にTesla® K80カード1枚のGK210チップ2つを用いた2並列計算を実行した結果を示します。(縦軸は性能を ns/day単位でプロットおり、高い程パフォーマンスが良いことを表しています)
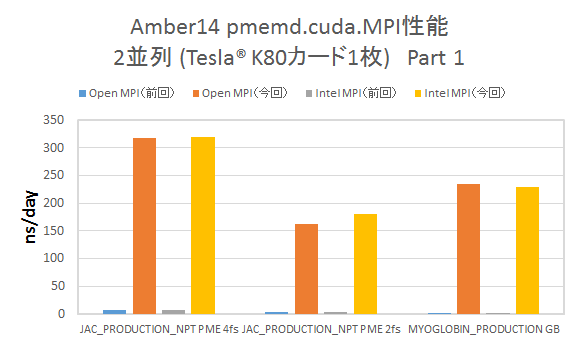
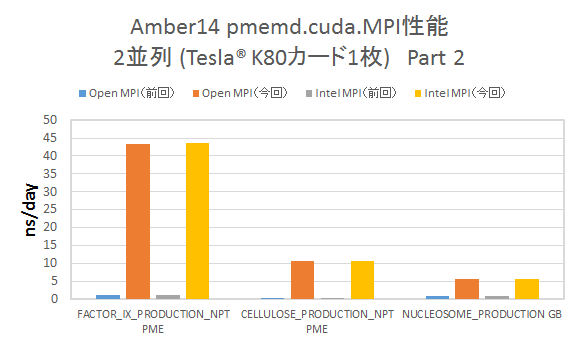
- 前回の検証と異なり、計算は特に問題なく終了し、グラフに示した通り、パフォーマンスの大幅な改善が見られます。このことから、前回確認されたP2P通信時のボトルネックが解消したことが分かります。
▶Tesla® K80カード2枚をまたいだ2並列計算 CUDA_VISIBLE_DEVICES環境変数を用いて、明示的にTesla® K80カード2枚を用いて2並列計算を実行した結果を示します。
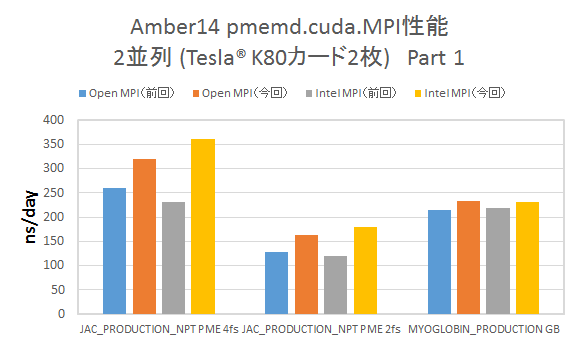
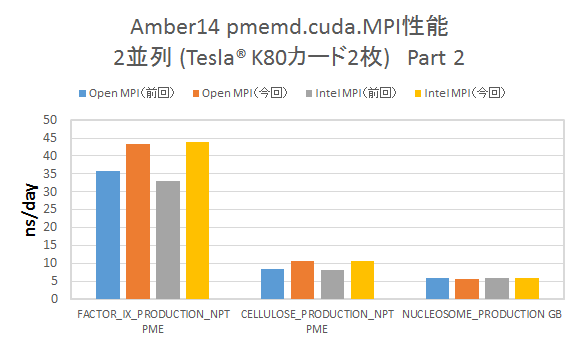
- Tesla® K80カード1枚での2並列計算程ではありませんが、多くのインプットにおいてパフォーマンスの改善が見られます。
今回の検証では、カード2枚の場合でも、Amber14のログファイル中にP2P通信を行っている旨の記述が見られました。前回の検証では異なるK80間はP2P通信が不可能でしたが、この点も解消されている模様です。今回のベンチマークでのパフォーマンス向上は、P2P通信の採用により、GPU間の通信に起因するボトルネック要因が改善され、パフォーマンスの向上につながったため、と推測されます。
以上の検証から、BIOSを更新し、さらにLinux OS上で Tesla® K80に関するPCI設定変更を行ったことで、Tesla® K80 カード内、カード間ともに、P2P通信が正常に行え、動作および性能において不具合は発生していないと考えられます。前回は、P2P通信に関する問題から、“Amber14 GPU計算用途としては、Tesla® K80 はお勧めいたしかねます”、という報告をいたしましたが、今回の検証結果により、“必要なBIOS更新およびPCI設定変更を行うことで、Tesla® K80はAmber14 用途でも想定通りの動作、性能が発揮できる”という結論に変更いたします。
アプリケーションにあわせて最適なハードウェア構成をご提案いたします
弊社では、GROMACS、Amberをはじめとする種々の実用アプリケーションのGPU版について、最新ハードウェアにて動作検証とチューニングを行っています。
GROMACS、Amber以外のアプリケーションにつきましてもベンチマークが可能です。ベンチマークで得た知見をもとにアプリケーションの実効性能を最大限に高める最適なハードウェア構成をご提案いたします。GPGPU計算環境のセットアップは弊社にお任せください。
・Intel、インテル、Intelロゴ、Xeon、Xeon Inside は、米国およびその他の国におけるIntel Corporationの商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



お問い合わせ
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)