
Technical Information
技術情報
インテル® Xeon Phi™の検証結果
インテル® Xeon Phi™の検証結果をスライド形式でわかりやすくお伝えします。

- Phiは1GHz 200コア(物理50コア × Hyper Threading 4スレッド)サーバと覚えます。

- つまり、このボードの中に、1GHzで動作するCPUを200コア搭載したLinuxサーバがある、と考えてください。大雑把ですが、それで実体をほぼあらわしています。

- 評価結果を端的に述べますと、Phiには有望3割、失望7割を感じました。詳細を説明いたします。まずは有望なデータから。
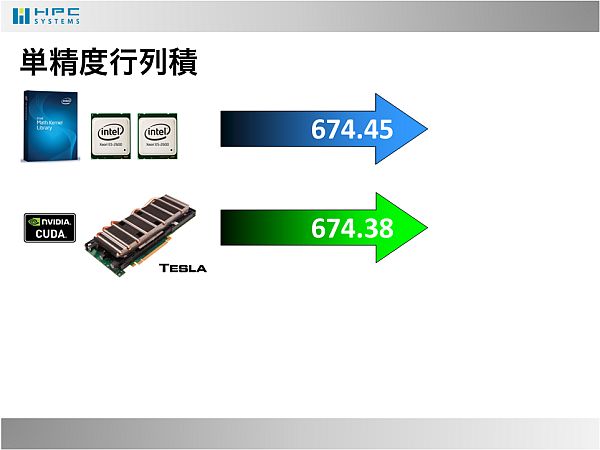
- 2012年現在、インテルのCPU E5-2600シリーズの1ノードとNVIDIAのTesla M2090の1枚は、単精度行列積の性能が674Gflops程度となっています。ベンチマークページ
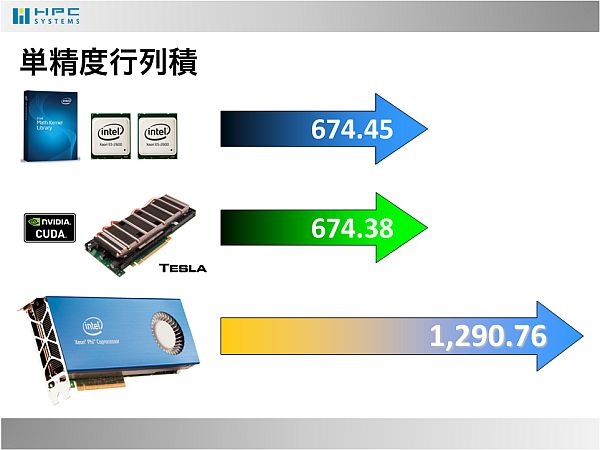
- そんな中、Phiは1枚で1290Gflops(従来比ほぼ2倍)の実効性能を達成しました!これは潜在的に強力な浮動小数点数演算性能を有していることをアピールしています。

- また、Phiは「従来のIAアーキテクチャのアプリケーションをそのまま使えることが最大の売り」と詠われてきました。これは本当かと言うと、

- 従来のIAアーキテクチャのアプリケーションが「そのまま動くこともあります」と注意喚起せざるをえない結果が確認されました。具体的には次の2点です。

- 動作が遅くなります。これは、コア周波数が約1GHzで動作するため、配列への初期値代入やシステムコールの呼び出しにおいて、動作速度が1GHzに低下します。並列化されていない処理では大きな速度低下につながります。

- メモリ不足で動かないことがあります。昨今のサーバ向けアプリでは数十GBよりも大きいメモリ環境を想定する場合が多いため、その感覚で計算を実行させると、たちまちメモリ不足で計算を実行できなくなります。

- これら①②の原因と解決策を記します。

- Phi向けのプログラムの開発には、2012年11月現在、基本的に、インテルComposer XE 2013以降、MPIにはインテルMPI 4.1以降しか選択肢がありません。

- インテル Composer XEでPhi向けにコンパイルしなおすには -mmic オプションと -no-offload オプションを併用してコンパイルします。こうするとPhi上で動作するELFをクロスコンパイルできます。しかし、従来のサーバ環境と同じハードウェア要件を想定してしまうため、上記①②のように、遅かったり、メモリ不足となったりします。
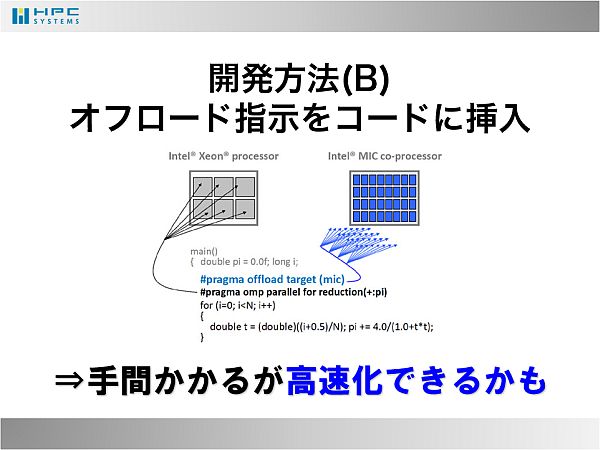
- この問題を回避するには、ソースコードの一部だけをPhi上で実行させるように、ソースコードにオフロード指示を挿入するという策が考えられます。GPGPUでいうところのOpenACCのような指示文です。この方法は、ソースコードを手直しする手間がかかりますが、高速化できる可能性を秘めています。

- 以下に、開発方法(A)、すなわち単にクロスコンパイルしただけでのベンチマーク結果を記します。

- 試したソフトウェアは左図のとおりです。
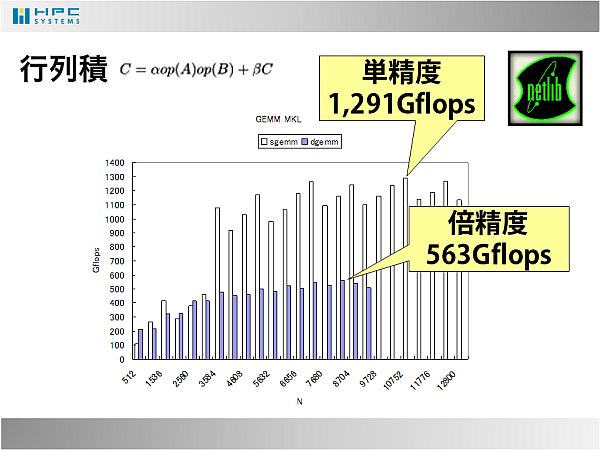
- 行列積は行列サイズを変えながらベンチマーク取得しました。単精度では1291Gflops、倍精度では563GflopsをPhi1枚で達成しました。
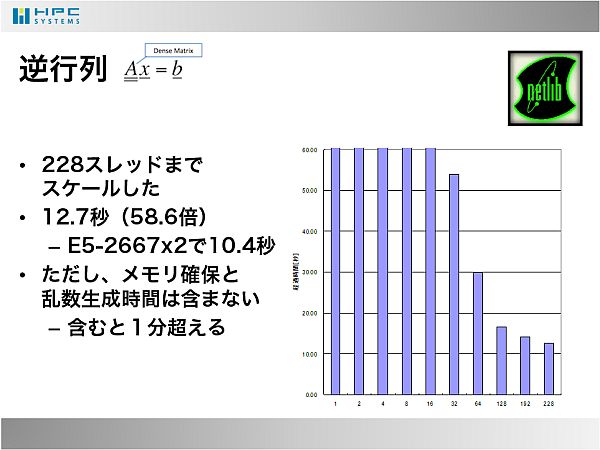
- 逆行列はサイズ一定のまま並列数(OpenMPスレッド数)を増やしながらベンチマーク取得しました。228スレッドまでスケールしましたが、その性能はE5-2600シリーズに及ばないものでした。なお、配列メモリの確保と、乱数で初期化する処理においては、並列化していないため1GHzで動作し、とても遅くなっていました。
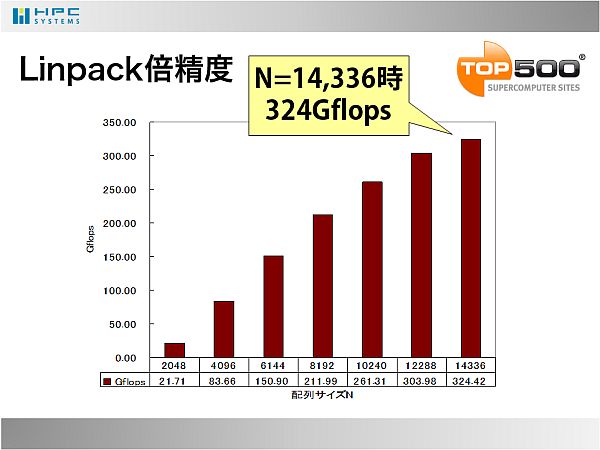
- Linpackでは配列サイズをメモリいっぱいまで使い切るように増やしながらベンチマーク取得しました。最大時、324Gflopsを達成しました。

- HPLはコンパイル・リンクできましたが、N=4000を試したところ異常動作していたようで計算が完了しませんでした。不具合原因については究明しきれませんでした。
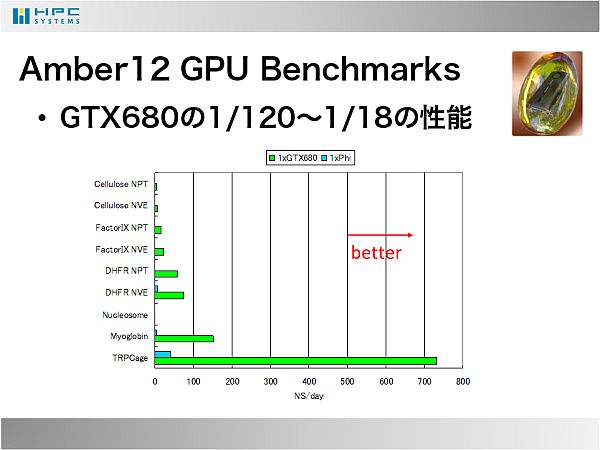
- Amber12ではGPU Benchmarksページに記載されているベンチマークを取得しました。おそらくオフロードを駆使していない所為でしょう、GTX680の性能のわずか18分の1の性能しか達成できませんでした。
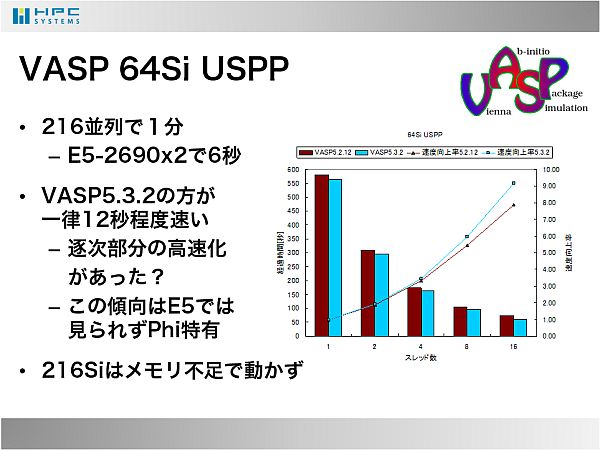
- VASPでは5.2.12と5.3.2をビルドしてみました。64個のSi原子でのUSPP計算をさせたところ16並列までスケールし、16並列で1分かかりました。しかしこれはE5-2600シリーズではわずか6秒で終わる計算です。216原子ではメモリ不足で動作しませんでした。

- まとめます。

- Phiでは、単精度行列積で1291Gflopsを1枚で達成するという華々しい性能が見られました。しかしその一方で、ソースコードを書き換えないと、実アプリケーションでは遅くてメモリ不足で話にならないこともわかりました。さて、一体誰がソースコードを書き換えるのでしょうか?

- ソースコード書き換えには手間とお金が必要です。それらに対して、インテル社がどの程度投資するのかがPhiの普及度合いを握っているでしょう。弊社はこの先もPhiの動向を注視していきます。
★続報はこちらから
・Intel、インテル、Intel ロゴ、Xeon、Xeon Inside、Xeon Phi は、アメリカ合衆国およびその他の国における Intel Corporation の商標です。
・NVIDIA、NVIDIA ロゴ、CUDAおよびTeslaは、米国及びその他の国におけるNVIDIA Corporationの商標または登録商標です。
・その他、記載されている会社名、製品名、サービス名等は、各社の商標または登録商標です。



Contact
お問い合わせ
お客様に最適な製品をご提案いたします。まずは気軽にお問い合わせ下さい。
03-5446-5531
(平日9:30~17:30土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)