NVIDIA® Tesla® シリーズを
最大10基搭載可能
最大10基搭載可能






| OS | 【HPC向け】CentOS, Red Hat Enterprise Linux 【Deep Learning向け】 Ubuntu ※Windowsを希望される場合は、別途ご相談ください。 |
|---|---|
| プロセッサー | インテル® Xeon® プロセッサー E5-2600 v4 ファミリー ※CPUモデル(プロセッサー・ナンバー)によって設置環境に制限があります。詳細はお問い合わせください。 |
| プロセッサー搭載数 | 最大2CPU (44コア) |
| プロセッサー冷却方式 | 空冷式 |
| チップセット | インテル® C612 |
| メモリ | 1.5TB (64GB DDR4 LRDIMM-2400 Registered ECC ×24) 1TB (64GB DDR4 LRDIMM-2400 Registered ECC ×16) 768GB (32GB DDR4-2400 ECC Registered ×24) 512GB (32GB DDR4-2400 ECC Registered ×16) 256GB (16GB DDR4-2400 ECC Registered ×16) 128GB (16GB DDR4-2400 ECC Registered ×8) 64GB (8GB DDR4-2400 ECC Registered ×8) |
| メモリスロット | 24DIMMスロット/DDR4 LRDIMM-2400 Registered ECC (64GB), DDR4 2400 Registered ECC (8,16,32GB) |
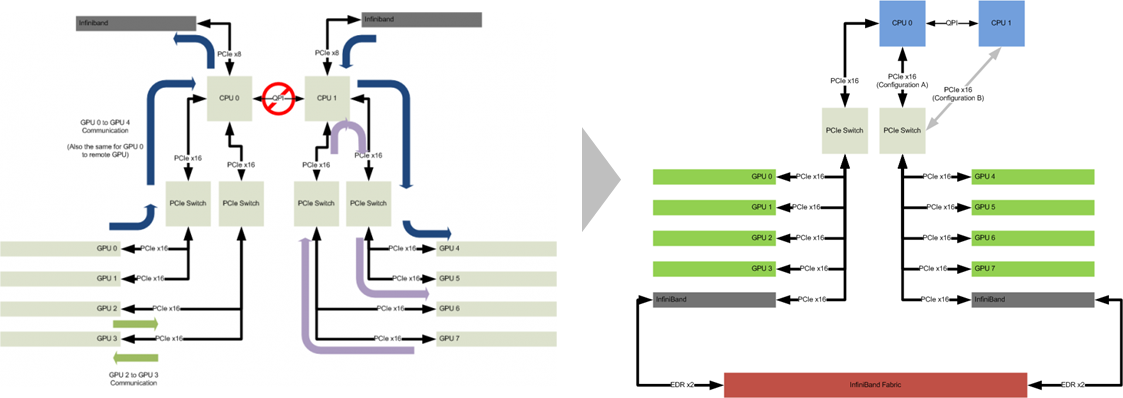
| GPGPUカード | NVIDIA® Tesla® V100 16GB |
| GPGPUカード搭載数 | 最大10基 |
| ハードディスクドライブ | 標準:1TB (2.5型, SATA) ×2 ※2.5型 SATA HDD/SSDを最大24台搭載可能 ※RAIDアレイコントローラー(オプション)増設時、SAS HDD使用可能 |
| 光学ドライブ | なし |
| グラフィックス | Aspeed AST2400 |
| インターフェイス | VGA [D-sub15ピン] (背面) ×1 ※ビデオカード搭載時は出力機能をOFFに設定します。 USB3.0 (背面) ×4 ネットワーク [GbEポート] (背面) ×2 IPMI2.0ポート [RJ45] (背面) ×1 |
| 拡張スロット | PCI-Express 3.0 (x16) ×11, PCI-Express 3.0 (x8)(in x16) ×1 |
| 電源ユニット | 2000W 冗長化電源 (80PLUS TITANIUM認証取得) |
| ACケーブル | 100V用ACケーブルを4本添付/IEC320-C13 IEC320-C13 ⇒ NEMA 5-15P NEMA5-15P オプション:200V用ACケーブルを4本添付/ IEC320-C13 IEC320-C13 ⇒ IEC320-C14 IEC320-C14 |
| ACコネクタタイプ | IEC 320-C14 |
| 最大消費電力 | ー |
| 筐体タイプ | ラックマウントタイプ (4U) |
| サイズ (縦幅×横幅×奥行) | 178mm × 437mm × 737mm |
| 重量 | 41kg |
| 附属品 | 100V用ACケーブル ×4 USBキーボード (日本語または英語) ×1 USB光学式スクロールマウス ×1 取扱説明書 保証書 |
| 保証 | 3年間センドバック保守 |
| オプション | RAIDアレイコントローラー |
|---|---|
| 2.5型 SSD (フラッシュメモリドライブ) | |
| InfiniBand HCA | |
| 各種ディスプレイ |
※会社名及び製品名等は、当社及び各社の商標または登録商標です。価格、写真、仕様等は予告なく変更する場合があります。製品の色調及び仕様は実際と異なる場合があります。
平日9:30~17:30 (土曜日、日曜日、祝祭日、年末年始、夏期休暇は、休日とさせていただきます。)